Trie
Trie
Trie 專門用於儲存和快速查找字串
O(n) 查詢會比在一般的陣列 O(m*n) 中還快
副作用是空間複雜度很高
別名:字典樹、前綴樹
要點
觀念
每個節點內會有
- unordered_map,key 為下一個字元,value 該字元的節點 pointer
- 布林變數,用於紀錄該節點是否為一個字串的結束點
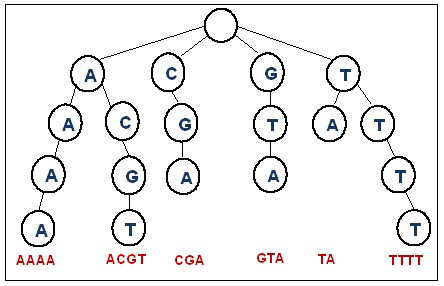
圖片引用自 這裡
功能
- insert:插入字串
- search:查詢字串是否存在
- delete:刪除字串
實作
結構本體
1
2
3
4
struct Node {
unordered_map<char, Node*> child;
bool isWord = false;
};宣告結構
1
Node *root = new Node;插入
從根節點開始往下尋找有無特定字元的子節點
若沒有子節點,新增一個子節點
接著移動到下一個節點
移動到最後一個字元時,設定 isWord 為 true 以記錄該節點為字尾
1
2
3
4
5
6
7
void insert(Node *p, string s) {
for (auto c : s) {
if (!p -> child[c]) p -> child[c] = new Node;
p = p -> child[c];
}
p -> isWord = true;
}查詢
從根節點開始往下尋找有無特定字元的子節點
如果子節點存在,往下移動
如果不存在,則回傳 false
移動到最後一個字元時,檢查 isWord 是否為 true,並回傳
1
2
3
4
5
6
7
bool search(Node *p, string s) {
for (auto c : s) {
if (p -> child[c]) p = p -> child[c];
else return false;
}
return p -> isWord;
}刪除
從第一個字元遞迴到最後一個字元刪除
到字尾時,將 isWord 設為 false
檢查每個節點,若無子節點且 isWord 為 false 就刪除
不論有無刪除,將該節點回傳給上一級作為子節點(若刪除則回傳 nullptr)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Node *remove(Node *root, string s, int depth = 0) {
if (!root) return nullptr;
if (depth == s.size()) {
if (root -> isWord) root -> isWord = false;
if (root -> child.empty()) {
delete root;
root = nullptr;
}
return root;
}
char c = s[depth];
if (root -> child[c]) {
root -> child[c] = remove(root -> child[c], s, depth + 1);
if (root -> child.empty() && !root -> isWord) {
delete root;
root = nullptr;
}
return root;
}
}補充:如果輸入有可能是空字串,記得補上邊界判斷